
Recently I had to profile (i.e. explore and analyse) a reasonably large database for a client. While there are plenty of applications available to do this, I wanted the flexibility, power, and 'executable document' that Python/Pandas in a Jupyter Notebook offers.
I found a fantastic package called pandas-profiling which profiles tabular data in a pandas dataframe (which can easily be read from a database table or CSV), and produces a nice HTML-based report (excerpt below)...
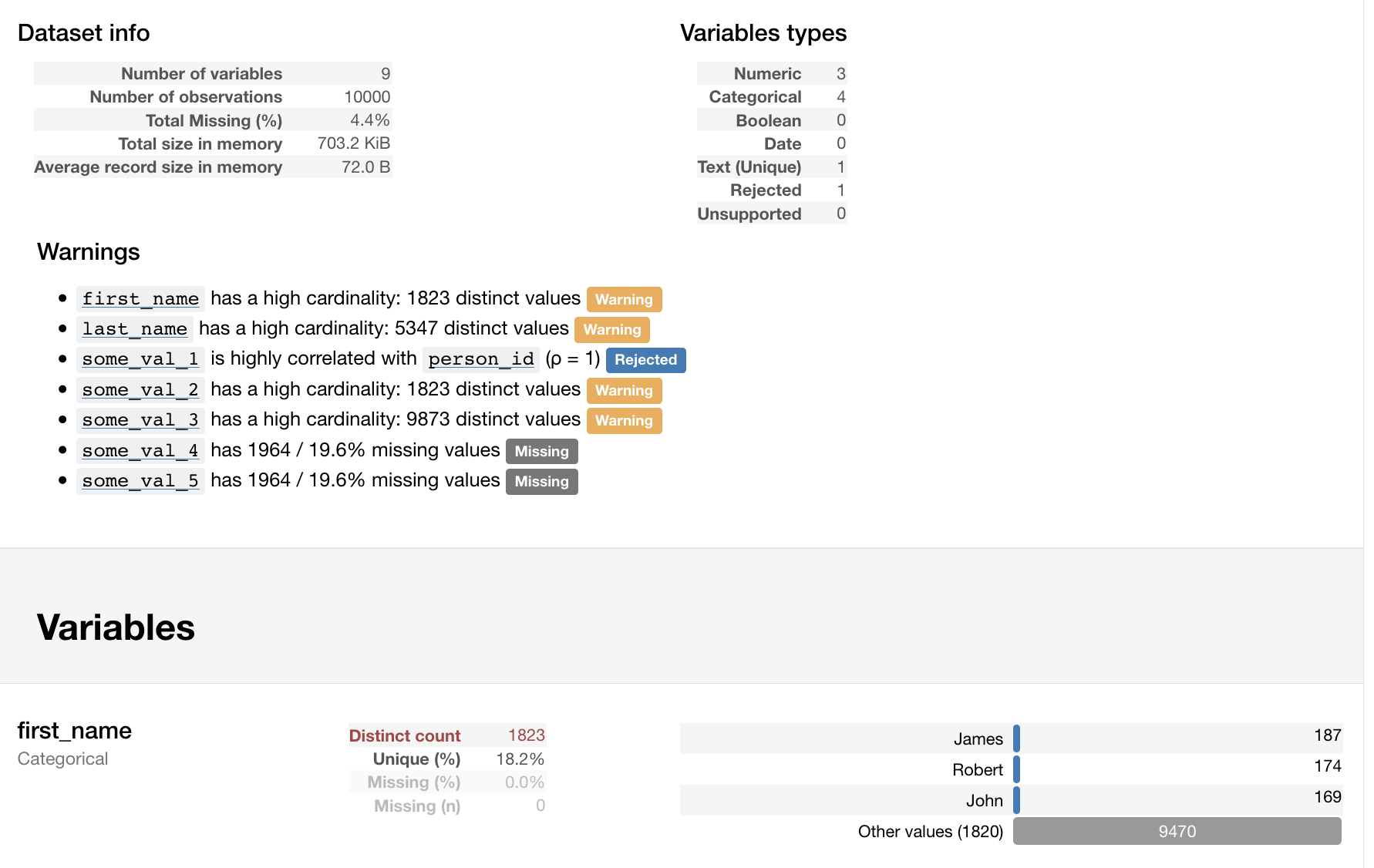
The project provides a good example of profiling meteor data, but I thought I'd provide a simpler alternative. A Jupyter Notebook is in my github account.
While you'd usually be iterating through database tables or CSVs and loading each into a dataframe, here I'm generating a dataframe from a python dictionary.
Setup
Uses 'names' package for generating random person names.
import pandas as pd
import numpy as np
import random
import names # random name generator - pip install names
import pandas_profiling # pip install pandas_profiling
Create Mock Data
n records of fake person data, with nonsensical attributes to exercise pandas-profiling's statistical analysis.
mock_data = []
for x in range(10000):
person_id = x
first_name = names.get_first_name()
last_name = names.get_last_name()
phone_number = '+61-{}-{:04d}-{:04d}'.format(
random.randint(2, 9),
random.randint(1, 9999),
random.randint(1, 9999)
)
some_val_1 = person_id + 1
some_val_2 = first_name[::-1] # reversed via slice
some_val_3 = last_name + first_name
# randomly leave last two attributes blank for some records
if random.randint(1, 5) == 1:
some_val_4 = np.NaN
some_val_5 = np.NaN
else:
some_val_4 = person_id * random.randint(1, 9)
some_val_5 = random.randint(-9999999, 9999999)
person_record = {
'person_id': person_id, 'first_name': first_name, 'last_name': last_name,
'phone_number': phone_number, 'some_val_1': some_val_1, 'some_val_2': some_val_2,
'some_val_3': some_val_3, 'some_val_4': some_val_4, 'some_val_5': some_val_5
}
mock_data.append(person_record)
Calling print(mock_data[0]) will produce something like:
{'person_id': 0, 'first_name': 'Elizabeth', 'last_name': 'Natale', 'phone_number': '+61-4-9966-5937', 'some_val_1': 1, 'some_val_2': 'htebazilE', 'some_val_3': 'NataleElizabeth', 'some_val_4': 0, 'some_val_5': -4809518}
Build Dataframe
df = pd.DataFrame.from_dict(mock_data)
Generate Report
Obviously display() requires a Jupyter notebook. Alternately you can output to file.
profile = pandas_profiling.ProfileReport(df)
display(profile)
# can output to file...
# profile.to_file(outputfile="/tmp/myoutputfile.html")
For large datasets the analysis can run out of memory, or hit recursion depth constraints; especially when doing correlation analysis on large free text fields (e.g. millions of records, >1 field with text longer than 255 chars). This can be disabled like so:
profile = pandas_profiling.ProfileReport(df, check_correlation = False)
EDIT: I suspect that this is caused by out-of-range datetime values - see this issue for more details.
Also, the number of records (or fields) analysed can be curtailed in the initial database query or by truncating the dataframe.
You can see the resulting report here.